







/* 版权声明:可以任意转载,转载时请标明文章原始出处和作者信息 .*/
author: 张俊林
关于阅读理解,相信大家都不陌生,我们接受的传统语文教育中阅读理解是非常常规的考试内容,一般形式就是给你一篇文章,然后针对这些文章提出一些问题,学生回答这些问题来证明自己确实理解了文章所要传达的主旨内容,理解地越透彻,学生越能考出好的成绩。
如果有一天机器能够做类似于我们人类做阅读理解任务,那会发生什么呢?很明显教会机器学会阅读理解是自然语言处理(NLP)中的核心任务之一。如果哪一天机器真能具备相当高水准的阅读理解能力,那么很多应用便会体现出真正的智能。比如搜索引擎会在真正理解文章内容基础上去回答用户的问题,而不是目前这种以关键词匹配的方式去响应用户,这对于搜索引擎来说应该是个技术革命,其技术革新对产品带来的巨大变化,远非在关键词匹配之上加上链接分析这种技术进化所能比拟的。而众所周知,谷歌其实就是依赖链接分析技术起家的,所以如果机器阅读理解技术能够实用化,对搜索引擎领域带来的巨变很可能是颠覆性的。对话机器人如果换个角度看的话,其实也可以看做是一种特殊的阅读理解问题,其他很多领域也是如此,所以机器阅读理解是个非常值得关注的技术方向。
深度学习近年来在NLP中广泛使用,在机器阅读理解领域也是如此,深度学习技术的引入使得机器阅读理解能力在最近一年内有了大幅提高,本文对深度学习在机器阅读理解领域的技术应用及其进展进行了归纳梳理。
什么是机器阅读理解
机器阅读理解其实和人阅读理解面临的问题是类似的,不过为了降低任务难度,很多目前研究的机器阅读理解都将世界知识排除在外,采用人工构造的比较简单的数据集,以及回答一些相对简单的问题。给定需要机器理解的文章以及对应的问题,比较常见的任务形式包括人工合成问答、Cloze-style queries和选择题等方式。
人工合成问答是由人工构造的由若干简单事实形成的文章以及给出对应问题,要求机器阅读理解文章内容并作出一定的推理,从而得出正确答案,正确答案往往是文章中的某个关键词或者实体。比如图1展示了人工合成阅读理解任务的示例。图1示例中前四句陈述句是人工合成的文章内容,Q是问题,而A是标准答案。

图1. 人工合成阅读理解任务示例
Cloze-style queries是类似于“完形填空”的任务,就是让计算机阅读并理解一篇文章内容后,对机器发出问题,问题往往是抽掉某个单词或者实体词的一个句子,而机器回答问题的过程就是将问题句子中被抽掉的单词或者实体词预测补全出来,一般要求这个被抽掉的单词或者实体词是在文章中出现过的。图2展示了完形填空式阅读理解任务的示例。图中表明了文章内容、问题及其对应的答案。这个例子是将真实的新闻数据中的实体词比如人名、地名等隐去,用实体标记符号替换掉实体词具体名称,问题中一般包含个占位符placeholder,这个占位符代表文章中的某个实体标记,机器阅读理解就是在文章中找出能够回答问题的某个真实答案的实体标记。目前的各种阅读理解任务中“完形填空式”任务是最常见的类型。

还有一种任务类型是选择题,就是阅读完一篇文章后,给出问题,正确答案是从几个选项中选择出来的,典型的任务比如托福的听力测试,目前也有研究使用机器来回答托福的听力测试,这本质上也是一种阅读理解任务。

如果形式化地对阅读理解任务和数据集进行描述的话,可以将该任务看作是四元组:
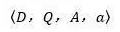
其中,D代表一篇文章,Q代表针对文章内容提出的一个问题,A是问题的正确答案候选集合,而a代表正确答案。对于选择题类型来说,就是明确提供的答案候选集合而是其中的正确选项。对于人工合成任务以及完形填空任务来说,一般要求:
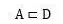
也就是说,要求候选答案是在文章中出现过的词汇或者实体词。
深度学习技术进展
本节内容对目前机器阅读理解领域中出现的技术方案进行归纳梳理,正像本文标题所述,我们只对深度学习相关的技术方案进行分析,传统技术方案不在讨论之列。
1 文章和问题的表示方法
用神经网络处理机器阅读理解问题,首先面临的问题就是如何表示文章和问题这两个最重要的研究对象。我们可以从现有机器阅读理解相关文献中归纳总结出常用的表示方法,当然这些表示方法不仅仅局限于阅读理解问题,也经常见于NLP其他子领域中。
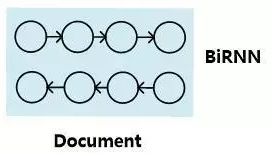 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









